Parallelizing for Loops in Python
- 11/14/2021
- Update: 7/5/2022
- Python
When you want to perform the same operation on multiple files in Python, processing them one by one can be slow, so we aim to speed up through parallelization. This page provides templates.
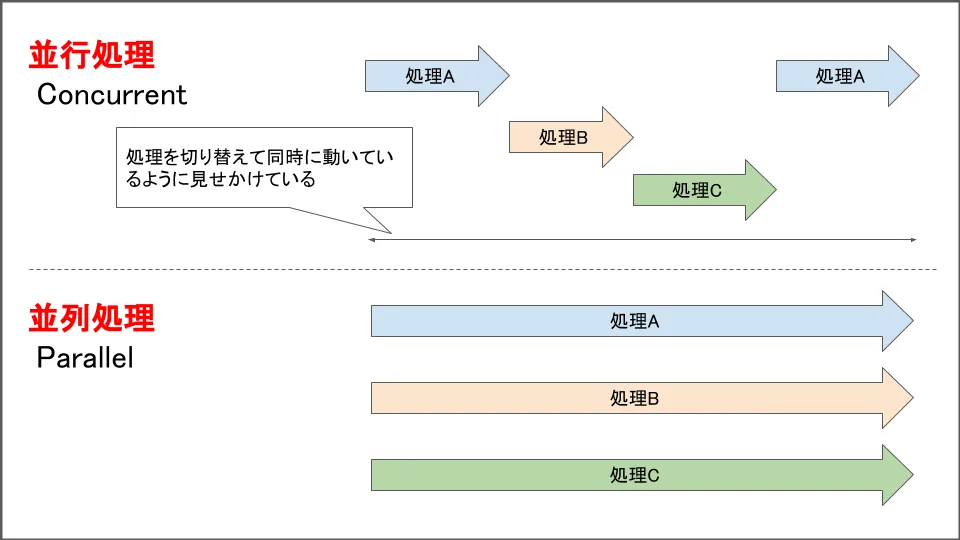
Concurrency vs Parallelism
In English, these are expressed as follows:
- Concurrency: 並行処理
- Parallelism: 並列処理
Leaving the detailed discussion to other literature, a simple explanation is:
- Concurrency is performing multiple processes within a certain time range.
- Parallelism is performing processes simultaneously within a certain time range.
Concurrency only does one job at the same time, but speeds up by making small progress on each process or by doing other processes when the CPU is idle during one process’s wait time. In other words, it speeds up by efficiently switching between processes.
Parallelism speeds up by performing multiple tasks simultaneously at the same time.
Concurrency speeds up by eliminating waste, while parallelism speeds up by increasing the number of lanes.
Illustrated, it looks like this:
Quoted from (https://blog.framinal.life/entry/2020/04/05/204055)
Threads and Processes
A process is the execution unit of one program. A thread is the execution unit within a process. Multiple threads exist within a process. In other words, the execution unit of a CPU core is a thread.
Threads can share the same memory space within a process, but processes have their own memory space allocated for each process, so inter-process communication is needed to share data.
In Python, due to GIL, it’s difficult to speed up CPU-bound (high-load processing) with threads. Therefore:
- Use multithreading for I/O-bound processing
- Use multiprocessing for CPU-bound processing
Implementation in Python
To implement parallel/concurrent processing in Python, there are the following methods (standard library):
- Concurrency
- threading
- concurrent.futures
- Parallelism
- multiprocessing
- concurrent.futures
concurrent.futures is a wrapper for threading and multiprocessing added in Python 3.2.
Since the code becomes simpler, use this for now.
As mentioned earlier, due to Python’s GIL, speed improvements through threading are not very expected, so parallel processing with multiprocessing is often faster.
Parallel Processing Code Example
Update 2022.07.05: There was a serious error in the source code example. My apologies.
The example below is for multiprocessing. To make it multithreading,
just change ProcessPoolExecutor to ThreadPoolExecutor.
If the function fn below is I/O-bound, use multithreading; if it’s CPU-bound, use multiprocessing.
from concurrent.futures import ProcessPoolExecutor
from tqdm import tqdm
import os
import time
def fn(idx, d): # -------------------(1)
# Functionalize the processing of one unit of the for loop
time.sleep(0.1)
return idx, d
def fn2(d): # -------------------(1)
# Functionalize the processing of one unit of the for loop
time.sleep(0.1)
return d
def main():
data = list(range(1000))
# When you want to know progress with tqdm
with tqdm(total=len(data)) as progress:
# 1. When there are objects that cannot be iterated as arguments
with ProcessPoolExecutor(max_workers=os.cpu_count() // 2) as executor: # -----(2)
futures = [] # List to store processing results
for i, d in enumerate(data): # -------(3)
future = executor.submit(fn, i, d)
future.add_done_callback(lambda p: progress.update()) # When you want to know progress with tqdm
futures.append(future)
result = [f.result() for f in futures]
# 2. When arguments can be iterated
with ProcessPoolExecutor(max_workers=os.cpu_count() // 2) as executor: # -----(2)
result = list(tqdm(executor.map(fn2, data), total=len(data)))
if __name__ == "__main__":
main()Made it possible to check progress with tqdm.
- Write out the range of processing you want to parallelize into a function ((1) fn function, or (2) fn2 function when passing array elements one after another like data with only one argument)
- Within
with ProcessPoolExecutor(max_workers=worker_num) as executor:, pass the function and its arguments to executor withsubmit or map.
For point 2, if the function arguments can be iterated, you can use map to omit the for loop in (3).

