How to Release HuggingFace (PyTorch) Models from RAM/VRAM
- 1/27/2025
- Update: 1/27/2025
- PyTorch
Hello. This time I’ll write about how to unload previously loaded HuggingFace models and release memory for both CPU RAM and GPU VRAM. While I mention HuggingFace, the methods introduced in this article can also be used for PyTorch models.
Since I experimented with several approaches, I’ll first state the conclusions about memory release methods, then explain what methods I tried and the mechanisms of memory release.
Verification code is available in the following repository with Docker:
Also, this time targets NVIDIA GPUs. I don’t have a verification environment for ROCm (AMD GPU)…
Background
Though I said I’d start with conclusions, let me first consider scenarios where memory release is necessary. I think the representative scenario requiring memory release is “APIs that dynamically serve multiple models”. While there are many examples in the world of serving PyTorch models with FastAPI, a representative Python framework, most target only single models or load predetermined models. To actually provide and verify trained models as APIs quickly in an MLOps fashion, mechanisms to dynamically call new models are needed. For this, old models must be unloaded from memory as new models are called, otherwise RAM and VRAM will overflow, causing API outages. The methods introduced today can be applied to such scenarios, and I actually use them.
Memory Release Method - CPU Edition
When performing inference on CPU, release models from RAM as follows. Note this is only effective when Python is CPython (which is the case in most situations).
import ctypes
import gc
import platform
from transformers import AutoModel
def ctype_memory_release():
if platform.system() == "Darwin": # macOS
libc = ctypes.CDLL("libc.dylib")
libc.malloc_zone_pressure_relief(0, 0)
elif platform.system() == "Linux":
ctypes.CDLL("libc.so.6").malloc_trim(0)
model = AutoModel.from_pretrained("bert-base-uncased")
del model
gc.collect()
ctype_memory_release()Alternatively, by setting the environment variable MALLOC_TRIM_THRESHOLD_=-1 as shown below, memory release is possible without using ctypes:
"""
Execute this file with `MALLOC_TRIM_THRESHOLD_=-1 python main.py`
"""
import gc
from transformers import AutoModel
model = AutoModel.from_pretrained("bert-base-uncased")
del model
gc.collect()Here’s a graph showing memory usage transitions when actually loading and unloading multiple models. I measured memory consumption of the executing process with psutil. Source code is around here.
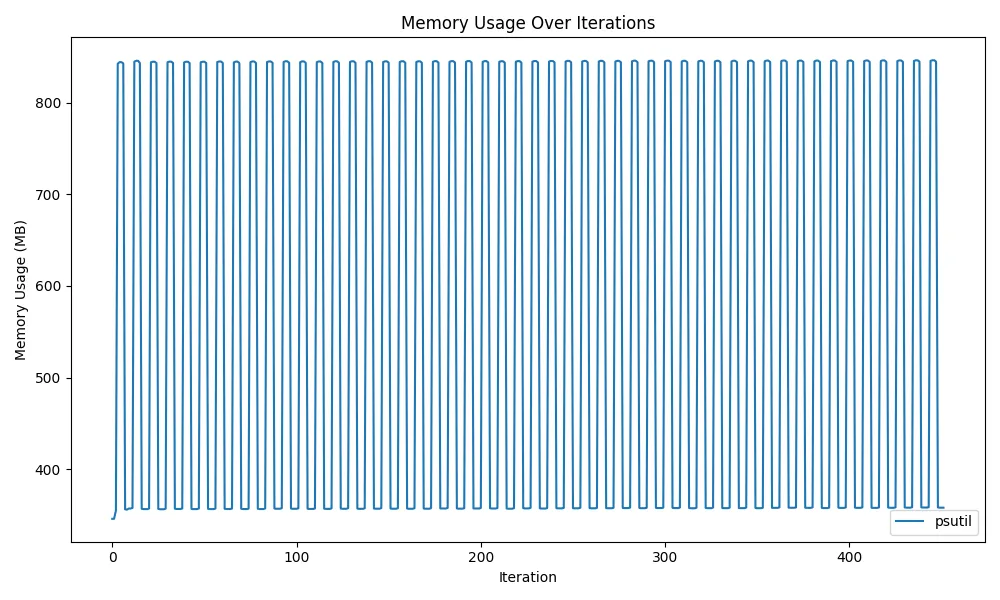
Since the graph values go up and down and continue horizontally, we can see that memory is being released correctly.
Memory Release Method - GPU Edition
Next, I’ll introduce memory release methods when loading memory to GPU:
import gc
import torch
from transformers import AutoModel
model = AutoModel.from_pretrained("bert-base-uncased")
del model
gc.collect()
torch.cuda.empty_cache()Similar to the CPU edition, after del model; gc.collect(), additionally calling torch.cuda.empty_cache() enables memory release.
Here’s a graph showing VRAM transitions. Measurement was done by checking memory usage occupied by processes with the nvidia-smi command.
Source code is around here.
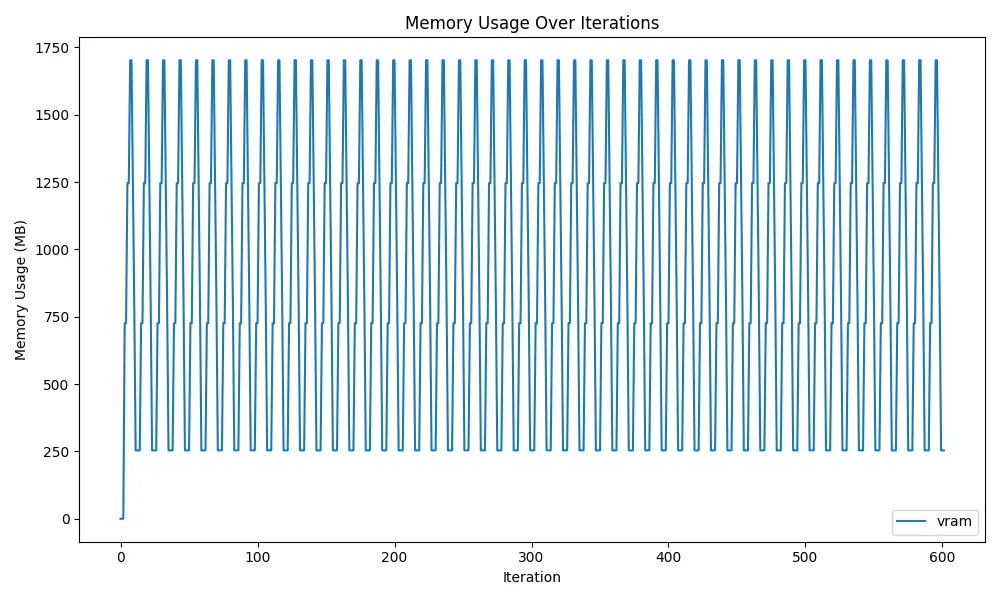
Since the graph goes up and down and continues horizontally, we can see that memory usage doesn’t monotonically increase and memory is being released correctly. However, compared to the CPU graph, memory doesn’t release down to near 0MB at the bottom during memory release. As I’ll explain later, this is the limit of release due to PyTorch and CUDA specifications. From when GPU usage first begins, 254MB cannot be released and remains in memory.
This concludes the specific methods for memory release that are the main conclusions of this article. From here, I’ll explain what I tried and the explanations for achieving memory release.
Memory Release Method Explanation - CPU Edition
First, regarding CPU memory release, I’ll touch on Python’s garbage collection. I’ll leave detailed explanations to other articles and provide minimal explanation here.
Garbage Collection
Garbage collection is a mechanism that automatically releases unnecessary memory among memory occupied by running programs, and is a common memory management method in other languages too. In Python’s case, automatic memory release is performed based on “reference counting” - the number of references to objects.
Here’s an actual example. As noted in code comments, when there are no more variables referencing an object, memory for the dict is released by garbage collection at arbitrary timing.
The del used in previous memory release code is an operation that deletes variables and decreases object reference count by 1.
(Actually, objects may not be released even when reference count becomes 0, but refer to other articles for this.)
# Variable a references dict, so reference count = 1
a = {"name": "mjun", "name": "Taro"}
# b also references it, so reference count = 2
b = a
# b stops referencing a's dict, so reference count = 1
b = {}
# a also stops referencing, so reference count = 0
# -> Memory released by garbage collection
a = NoneSince garbage collection is slow, it doesn’t perform memory release each time but at arbitrary timing.
To manually perform immediate memory release, use the standard gc module.
As follows, calling gc.collect() activates garbage collection and performs immediate memory release.

import gc
gc.collect()While it appears model memory release can be performed with the content so far, memory release cannot be performed with this method alone. Actually, as shown in the following figure, only partial memory can be released.
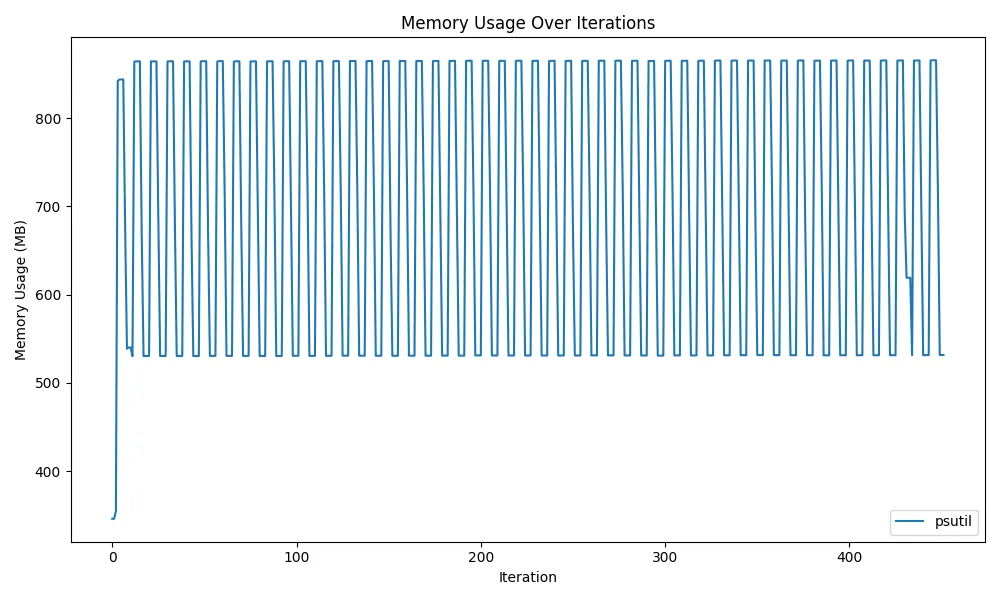
glibc’s dynamic mmap threshold
Now here’s the main topic. We found that gc.collect() mentioned above cannot release model memory. So we’ll dive into CPython, Python’s implementation, and further into the linked glibc.
By the way, running ldd $(which python) shows libc.so.6 linked to Python.
ldd $(which python)
linux-vdso.so.1 (0x00007ffe327fc000)
/home/mjun/.venv/bin/../lib/libpython3.11.so.1.0 => not found
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x000075b9061eb000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x000075b9061e6000)
libutil.so.1 => /lib/x86_64-linux-gnu/libutil.so.1 (0x000075b9061e1000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x000075b9060f8000)
librt.so.1 => /lib/x86_64-linux-gnu/librt.so.1 (0x000075b9060f1000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x000075b905e00000)
/lib64/ld-linux-x86-64.so.2 (0x000075b90620c000)In glibc, previously when the memory release function free was called, memory was immediately returned to the OS. However, when free calls are frequent, performance degrades, so changes were made to limit the proportion of returned memory (dynamic mmap threshold).
(Reference: https://jp.tenable.com/plugins/nessus/88777)
Due to this, the earlier gc.collect() alone doesn’t release all memory occupied by models.
To release model memory, all occupied memory must be returned immediately.
Looking at glibc’s mallopt(3) manual, environment variables are prepared to change this setting.
That’s MALLOC_TRIM_THRESHOLD_=-1. Setting this way causes memory to be returned to the OS immediately, enabling complete model memory release.
Since setting environment variables affects Python’s overall operation, there’s also a method to force memory release using glibc. That’s malloc_trim. Executing malloc_trim(0) releases as much heap memory as possible that the program isn’t using. To call glibc functions from Python:
import ctypes
ctypes.CDLL("libc.so.6").malloc_trim(0)This special method of calling C from Python also enables complete memory release.
I tried other methods but they had no effect:
- Manually deleting all model weights and gradients (torch.Tensor)
os.environ["MALLOC_TRIM_THRESHOLD_"] = "-1"
That concludes the CPU explanation. Next is GPU.
Memory Release Method Explanation - GPU Edition
GPU memory release is performed by combining PyTorch’s torch.cuda module used internally by HuggingFace.
First, here’s the result of attempting memory release using del model; gc.collect() without torch:
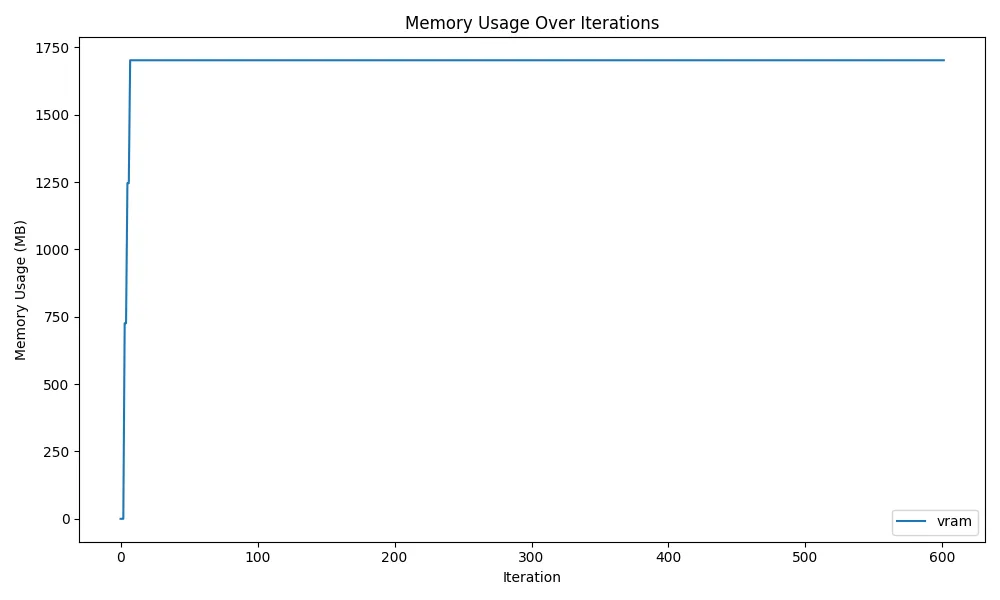
As you can see, VRAM isn’t released. This is because VRAM areas once allocated by PyTorch are retained as Reserved Memory even when not actually used. Normally, since VRAM read/write is frequent for model and Tensor transfers to GPU, the process reserves some memory for speedup, but when multiple users or processes use GPU, the reserved memory prevents other processes from securing VRAM.
So we use torch.cuda.empty_cache() defined in PyTorch’s torch.cuda module.
import torch
torch.cuda.empty_cache()This function releases unused Reserved Memory.
Here’s the VRAM transition figure using del model; gc.collect() and torch.cuda.empty_cache().
Source code is here.
Compared to before, VRAM usage goes up and down, showing memory is being released.
What’s concerning here is that about 254MB of initially allocated VRAM cannot be released. This is because PyTorch operates CUDA through contexts. CUDA’s context interface creates one context per process for handling GPU and manages GPU state. Since this state management uses some VRAM, 254MB cannot be released and remains.
Let’s actually see how much GPU VRAM is allocated when creating CUDA context in C++ CUDA.
Compile the following code with nvcc and check VRAM usage with nvidia-smi while executing:
#include <cuda_runtime.h>
#include <iostream>
int main() {
cudaSetDevice(0);
// Allocate and release some memory
const size_t size = 1 << 20; // 1 MB
void* d_ptr = nullptr;
cudaMalloc(&d_ptr, size);
cudaMemset(d_ptr, 0, size);
cudaFree(d_ptr);
// Check with nvidia-smi in another terminal
std::cout << "Check nvidia-smi in another terminal. Press Enter to exit." << std::endl;
std::cin.get();
return 0;
}nvcc main.cu
./a.out
Check nvidia-smi in another terminal. Press Enter to exit.
# In another terminal
nvidia-smi
Mon Jan 27 16:18:19 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 565.57.01 Driver Version: 565.57.01 CUDA Version: 12.7 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3090 On | 00000000:09:00.0 On | N/A |
| 44% 44C P0 106W / 350W | 2100MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 2502624 C ./a.out 254MiB |
+-----------------------------------------------------------------------------------------+Looking at the VRAM capacity of the ./a.out process at the bottom of nvidia-smi output shows 254MiB used, confirming that 254MB memory usage cannot be avoided while maintaining CUDA context.
At this point, you might think destroying CUDA context would release VRAM to 0, but actually PyTorch doesn’t anticipate such methods, and errors occur when trying to operate GPU again after destroying context once.
The code is this.
import ctypes
def cuda_device_reset():
libcudart = ctypes.cdll.LoadLibrary("libcudart.so")
# Get cudaDeviceReset symbol and set return/argument types
reset_func = libcudart.cudaDeviceReset
reset_func.restype = ctypes.c_int
reset_func.argtypes = []
reset_func()Traceback (most recent call last):
File "/app/7.py", line 56, in <module>
main()
File "/app/7.py", line 41, in main
torch.cuda.empty_cache()
File "/opt/venv/lib/python3.11/site-packages/torch/cuda/memory.py", line 192, in empty_cache
torch._C._cuda_emptyCache()
RuntimeError: CUDA error: invalid argument
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.So to completely zero VRAM usage, you need to kill the entire process. While you can’t completely zero VRAM usage, model unloading itself can be performed with the introduced methods.
I tried other methods:
torch.cuda.ipc_collect()torch._C._cuda_clearCublasWorkspaces()torch.backends.cuda.cufft_plan_cache.clear()
Since this time we’re only loading/unloading models, the above weren’t relevant, but when actually performing inference, VRAM consumption occurs in cuDNN and cuBLAS too, so they might be necessary.
That concludes the introduction to model loading/unloading. Those operating actual services should refer to this.

