When VRAM Imbalance Occurs During PyTorch DDP Multi-GPU Training
- 1/21/2023
- Update: 1/21/2023
- PyTorch
Hello. This time I’ll introduce a PyTorch tip - how to fix VRAM usage imbalance between GPUs that occurs during Multi GPU Training due to configuration deficiencies.
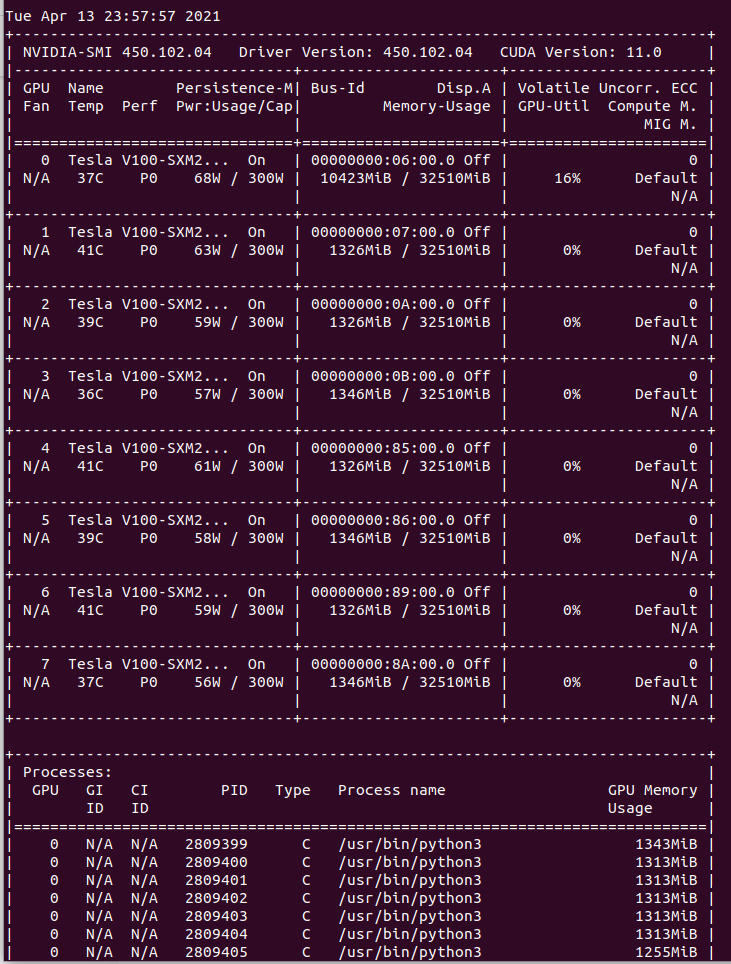
Basically, when VRAM usage imbalance occurs between GPUs, it’s often due to implementation mistakes.
When transferring weights, models, or tensors to GPU in PyTorch, many people use .to("cuda") or .cuda(), but if you don’t specify a GPU ID, it transfers to GPU with ID 0.
model = model.cuda()
t = torch.zeros((3, 256, 256)).to("cuda")In Distributed Data Parallel (DDP) or Data Parallel (DP), all GPUs being used are visible from the master node of the script executing training.
However, since tensors and models need to be transferred to each GPU, if you don’t specify GPU ID, everything gets transferred to GPU ID 0, causing VRAM usage imbalance.
You can specify the transfer GPU with .to("cuda:1") or .cuda(6), but this method makes it difficult to reuse code between Single GPU and Multi GPU training.
So by setting torch.cuda.set_device(), you can change the destination GPU when no ID is specified.
# Set Local Rank for Multi GPU Training
rank = int(os.environ.get("LOCAL_RANK", -1))
# Set Device
if cfg.CPU:
device = torch.device("cpu")
elif rank != -1:
device = torch.device(rank)
torch.cuda.set_device(rank)
else:
device = torch.device(0)
torch.cuda.set_device(0)In the above code, the variable rank can determine whether it’s DDP or Single GPU training.
During DDP, the environment variable LOCAL_RANK contains the ID of the training process executed within the machine, which can be used directly as the GPU ID.
During Single GPU training, with the above implementation, rank becomes -1, making it easy to distinguish from DDP cases.
Using the above implementation and the environment variable CUDA_VISIBLE_DEVICES, you should be able to easily select which GPUs to use.