PyTorch DDPでマルチGPU学習時にVRAMの偏りが発生した時
こんにちは.今回はPyTorchのTipsで,Multi GPU Training時に設定不足などで起こる, GPU間でのVRAMの使用量の偏りを直す方法を紹介します.
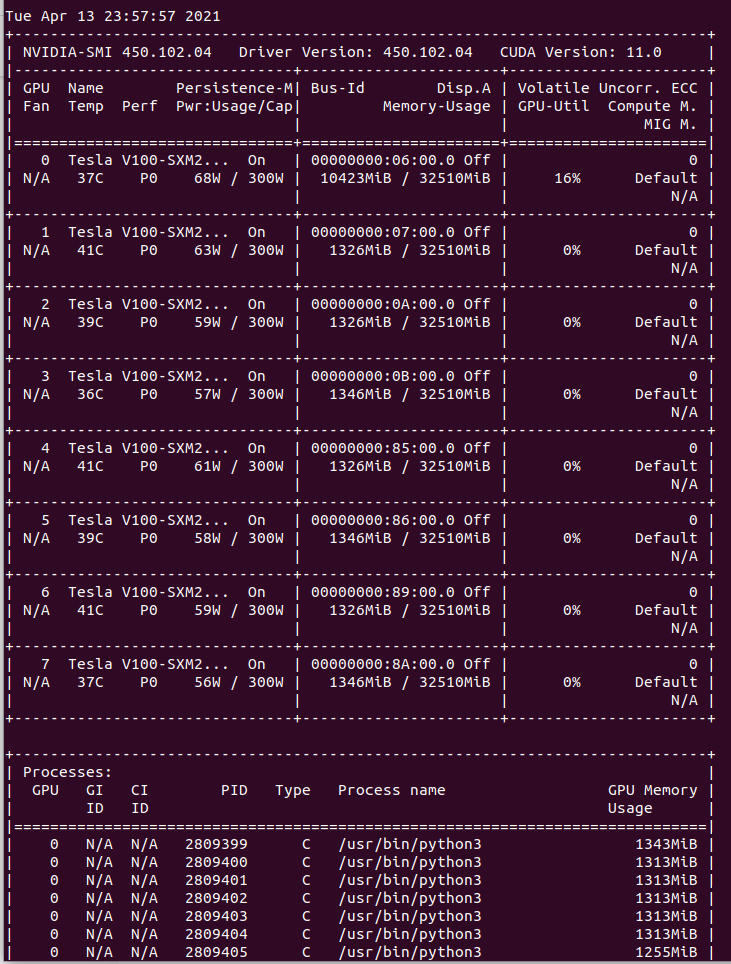
基本的にGPU間のVRAM使用量の偏りが起こる時は,実装のミスが多いです.
PyTorchで重みやモデルやテンソルをGPUへ転送する時に,.to("cuda")や.cuda()
で転送する人が多いと思いますが,GPUのIDを何も指定しないと,
IDが0のGPUへ転送されます.
model = model.cuda()
t = torch.zeros((3, 256, 256)).to("cuda")Distribute Data Parallel(DDP)やData Parallel(DP)では, 学習を実行するスクリプトのマスターノードからは,使用するGPUが全て見えている状態です.
しかし,テンソルやモデルは,それぞれのGPUに転送する必要があるため,GPUのIDを指定しないと全てID 0のGPUに転送されて しまい,VRAM使用量の偏りを起こしてしまいます.
.to("cuda:1")や.cuda(6)といった書き方で転送するGPUを指定することもできますが,
この方法だと,Single GPUとMulti GPUでの学習でコードを使いまわすことが難しくなってしまいます.
そこで,torch.cuda.set_device()を設定することで,IDを指定しなかった時の転送先GPUを変更することができます.
# Set Local Rank for Multi GPU Training
rank = int(os.environ.get("LOCAL_RANK", -1))
# Set Device
if cfg.CPU:
device = torch.device("cpu")
elif rank != -1:
device = torch.device(rank)
torch.cuda.set_device(rank)
else:
device = torch.device(0)
torch.cuda.set_device(0)上記のコードでは,変数rankでDDPかSingle GPUでの学習かを判断することができます.
DDP時には環境変数のLOCAL_RANKに計算機の中で実行される学習プロセスの
IDが振られており,これをそのままGPUのIDに利用することができます.
Single GPUでの学習時には上記の実装だと,rankは-1になるため
DDPとの場合分けも容易になります.
上記の実装と環境変数CUDA_VISIBLE_DEVICESを用いれば,容易に使用するGPUを
選択することができるかと思います.
参考